
Structuring the machine learning process
Amid testing, fiddling, and a lot of internal R&D-type activities, we tried to pull some threads of continuity through the processes our team was iteratively enacting in pursuit of data science. We took a hard look at our ML, Deep Learning, and Unsupervised Learning techniques, as well as our more traditional statistical approaches, and established a cycle that encompasses all the relevant steps while allowing for modification for non-traditional or specialized applications of data science.
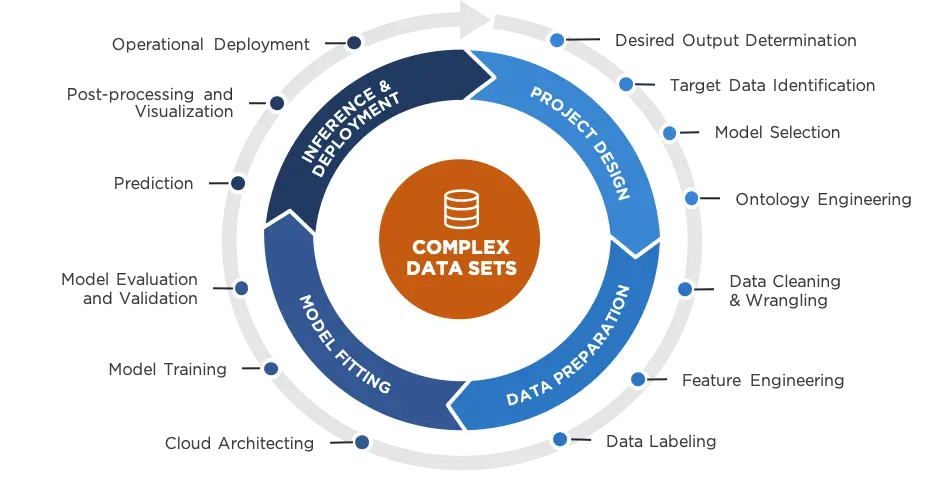
The resulting ML lifecycle facilitates our Agile AI process, generates repeatable processes, and contextualizes the challenges data science teams face when executing AI/ML. Within each quadrant, the tasks present “hidden challenges.” It is critical that the data science team addresses these challenges to ensure the initial “minimum viability” and eventual operations-level accuracy of the models produced in the cycle. The four quadrants are:
- Project Design
- Data Preparation
- Model Fitting
- Inference & Deployment
Quadrant One: Project Design
Not surprisingly, the first quadrant focuses on selecting the appropriate methods to address the predictive, analytic, or automation task at hand. It is one of the most difficult phases in the lifecycle and one that requires much collaboration between scientist and decision maker.
Because AI and ML have become buzzwords in the technical community, the biggest challenge in quadrant one comes down to determining whether the problem truly requires an ML solution. It is possible an advanced analytic, statistical, or another approach could suffice.
As a rule, the best way to determine whether an ML solution is required is to ask decision makers to complete one of the two following sentences:
“We need to automate X because…”
“We need to predict X because…”
The approach to this phase contains four steps:
- Desired Output Determination
- Target Data Identification
- Model Selection
- Ontology Engineering
While ontology engineering is arguably the most technically-involved step in the first quadrant, the biggest challenges occur in the process of identifying the target data available and determining the model best suited for the task. Once we’ve done those two things, it is on to the task on which the bulk of our time is spent: data wrangling.
![The [Hidden] Challenges of ML Series: Quadrant 1 Project Design](https://www.ntconcepts.com/wp-content/uploads/Green-umbrella-471497222_6000x2809-768x360.webp)
Quadrant Two: Data Preparation
A challenge familiar to any and all involved in data science is pre-processing and labeling data. The process of data wrangling (i.e., moving data to a central repository and transforming it into a schema conducive to ingest into a popular ML framework) ends up requiring much more time than the actual model tuning and testing itself. However, data labeling is the largest challenge as there seems to be no good way to avoid egregious human capital expenses and hours of tedious, error-prone work.
The specific steps within this phase are:
- Data Wrangling and Cleaning
- Feature Engineering
- Data Labeling
The stage that follows data preparation is often the phase people most readily associate with the field of data science. The third stage involves true data scientists (as opposed to data engineers and software developers) as rigorous testing and evaluation must be directed towards model tuning and performance.
![The [Hidden] Challenges of ML Series: Quadrant 2 Data Preparation](https://www.ntconcepts.com/wp-content/uploads/Green-umbrella-471497222_6000x2809-scaled.webp)
Quadrant Three: Model Fitting
Even though the bulk of the work happens during the data preparation and labeling phase (quadrant two), model preparation is the meat and potatoes of ML. This phase includes three steps:
- Cloud Architecting
- Model Training
- Model Evaluation and Validation
The most prominent challenge in this stage is in the precision mathematics (and a whole lot of trial and error) that lead to model validation through hyperparameter tuning and model testing.
Quadrant Four: Inference & Deployment
At this point in our ML Lifecycle, the team is prepared to leverage the model to make viable predictions, post-process the results, and visualize them. This is a joint effort that involves analysts, data scientists, and UI/UX engineers. In some cases, depending on the task, specialized visualization techniques are required such as post-process triangulation algorithms to calculate a more precise location for a predicted object. The three steps are:
- Prediction
- Post-processing and Visualization
- Operational Deployment
Assuming the model is generating accurate results that are visually represented, all that is left is for it to be used for its intended purpose. In the National Security environment, operational deployment of AI algorithms is one of the biggest challenges, both due to compute power constraints of downrange environments and discrepancies between unclassified training data and the mission data on which the model may be expected to perform inference.
Conclusion
Inherent across the ML Lifecycle, additional challenges exist such as model brittleness and bias. In subsequent articles, we will examine and address the challenges hidden within each quadrant in depth, along with some of the intangible influencers (such as bias) that can determine the success of using AI/ML to solve the most challenging questions.
Just getting started with ML and need to catch up quickly? Here are some ML 101 articles to get you up to speed!